
python如何实现日常工作自动化?
大多数作业具有可以自动执行的重复性任务,从而节省了一些宝贵的时间。这使自动化成为一项关键技能。一小撮熟练的自动化工程师和领域专家也许可以自动化整个团队中许多最繁琐的任务。那么python如何实现日常工作自动化?在本文中,我们将探讨使用Python(一种功能强大且易于学习的编程语言)的工作流自动化的基础。我们将使用Python编写一个简单而有用的自动化小脚本,该脚本将清理给定的文件夹并将每个文件放入相应的文件夹中。

我们的目标不是在一开始就编写完美的代码或创建理想的体系结构。我们也不会建立任何“非法”的东西。相反,我们将研究如何创建一个脚本,该脚本会自动清理给定的文件夹及其所有文件。
一、自动化领域和起点
自动化技术适用于大多数领域。对于初学者来说,它有助于完成诸如从一堆文档中提取电子邮件地址之类的任务,以便您可以进行电子邮件爆炸。或更复杂的方法,例如优化大型公司内部的工作流程和流程。
当然,从小型的个人脚本到替代实际人员的大型自动化基础架构涉及学习和改进的过程。因此,让我们看看您可以从何处开始旅程。
简单自动化
简单的自动化实现了快速直接的切入点。这可以涵盖小的独立过程,例如项目清理和目录内文件的重组,也可以包括工作流的某些部分,例如自动调整已保存文件的大小。
公共API自动化
公共API自动化是最常见的自动化形式,因为如今我们可以使用对API的HTTP请求来访问大多数功能。例如,如果您想在家中自动为自制的智能花园浇水。
为此,您想检查当天的天气,看看是否需要浇水或是否有雨来。
API逆向工程
在实际的漫游器中,基于API逆向工程的自动化更为常见,在下面的“道德注意事项”部分中,该图表的“ Bot Imposter”部分中也是如此。
通过对API进行反向工程,我们可以了解应用程序的用户流程。一个例子是登录在线浏览器游戏。
通过了解登录和身份验证过程,我们可以使用自己的脚本来复制该行为。然后,即使他们自己不提供应用程序,我们也可以创建自己的接口来使用该应用程序。
无论您要采用哪种方法,请始终考虑它是否合法。
您不想惹麻烦,对吗?
二、道德考量
GitHub上的某个人曾经与我联系并告诉我:
“喜欢和参与是数字货币,您正在贬值它们。”
这让我感到困惑,并让我质疑我为此目的而构建的工具。
这些互动和参与可以自动化并“伪造”的事实越来越多,这导致了社交媒体系统的扭曲和破坏。
如果人们不使用漫游器和其他互动系统,那么产生有价值和优质内容的人将对其他用户和广告公司不可见。
我的一个朋友想出了以下但丁与但丁的“地狱九圈”的联系,在每一步中,随着成为社会影响者的步伐越来越近,您将越来越不了解整个系统的实际破坏力。
我想在这里与您分享这件事,因为我认为这是我与InstaPy积极与网红合作时亲眼所见的非常准确的代表。
等级1:凌波-如果您;
等级2:调情 -当您手动喜欢并关注尽可能多的人时,请他们跟着您回去/喜欢您的帖子;
等级3:阴谋 -当您加入电报组喜欢和评论10张照片,因此接下来的10个人将喜欢和评论您的照片;
等级4:不忠 -当您使用低成本的虚拟助手代表您喜欢和关注时;
等级5:欲望-当您使用机器人给予喜欢,但没有得到任何回报(但您不为此付费(例如,Chrome扩展程序));
级别6:滥交-当您使用机器人给予50多个喜欢得到50多个喜欢的人,但您无需为此付费-例如,Chrome扩展程序;
等级7:贪婪或极端贪婪 -当您使用漫游器在200-700张照片之间点赞/关注/评论时,忽略了被禁止的机会;
等级8:卖淫 -当您支付未知的第三者服务进行自动对等时喜欢/关注您,但他们使用您的帐户喜欢/关注;
第9级:欺诈/异端 -当您购买关注者和喜欢并尝试将自己卖给有影响力的品牌时。
社交媒体上的恶意攻击程度如此之高,以至于如果您不进行机器人操作,那么您将被困在Limbo 1级,相对于同龄人而言,追随者的成长率和参与度都不高。
在经济学理论上,这被称为囚徒困境和零和博弈。如果我不机器人,而你又机器人,你赢了。如果您不是机器人,而我是机器人,我会赢。如果没有机器人,那么所有人都会赢。但是,由于没有人人都不要机器人,所以没有人能赢。
注:永远不要忘记整个工具对社交媒体的影响。
我们希望避免处理道德问题,而仍在此处从事自动化项目。这就是为什么我们将创建一个简单的目录清理脚本来帮助您整理凌乱文件夹的原因。
三、创建目录清理脚本
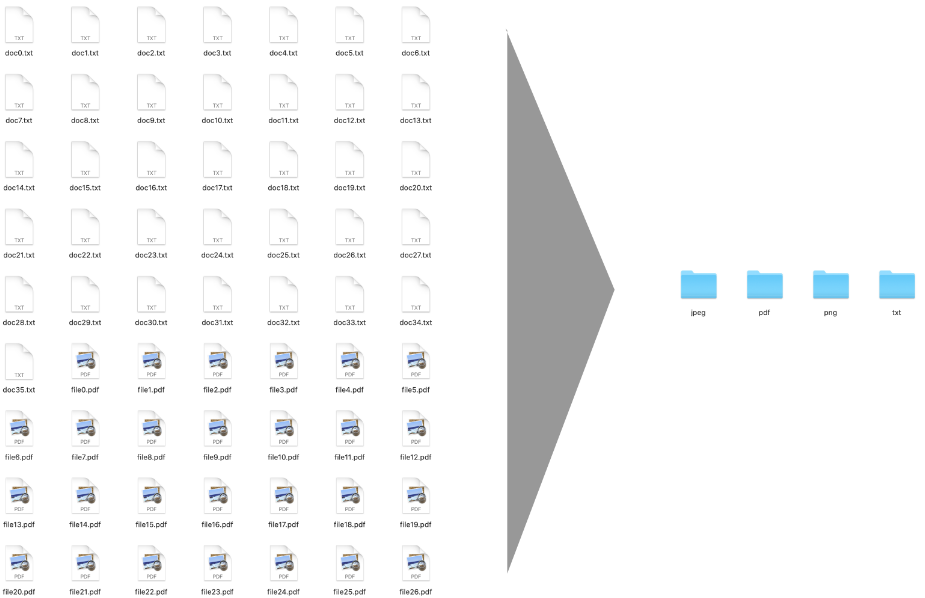
现在,我们要看一个非常简单的脚本。通过基于文件扩展名将这些文件移动到相应的文件夹中,它会自动清理给定目录。
因此,我们要做的就是:
1.设置参数解析器
由于我们正在使用操作系统功能(如移动文件),因此需要导入os库。除此之外,我们还希望使用户可以控制要清理的文件夹。我们将argparse为此使用库。
import os
import argparse
导入两个库之后,我们首先设置参数解析器。确保为每个添加的参数提供描述和帮助文本,以在用户键入内容时为用户提供有价值的帮助--help。
我们的论点将命名为--path。名称前面的双破折号告诉库这是一个可选参数。默认情况下,我们要使用当前目录,因此将默认值设置为"."。
parser = argparse.ArgumentParser(
description="Clean up directory and put files into according folders."
)
parser.add_argument(
"--path",
type=str,
default=".",
help="Directory path of the to be cleaned directory",
)
# parse the arguments given by the user and extract the path
args = parser.parse_args()
path = args.path
print(f"Cleaning up directory {path}")
这样就完成了参数解析部分–它非常简单易读,对吧?
让我们执行脚本并检查错误。
python directory_clean.py --path ./test
=> Cleaning up directory ./test
执行后,我们可以看到目录名称已完美打印到控制台。
现在让我们使用该os库来获取给定路径的文件。
2. 从文件夹中获取文件列表
通过使用该os.listdir(path)方法并为其提供有效路径,我们获得了该目录内所有文件和文件夹的列表。
在列出文件夹中的所有元素之后,我们不想在文件夹和文件夹之间进行区分,因为我们不想清理文件夹,而只清理文件。
在这种情况下,我们使用Python列表推导来遍历所有元素,如果它们满足作为文件或文件夹的给定要求,则将它们放到新列表中。
# get all files from given directory
dir_content = os.listdir(path)
# create a relative path from the path to the file and the document name
path_dir_content = [os.path.join(path, doc) for doc in dir_content]
# filter our directory content into a documents and folders list
docs = [doc for doc in path_dir_content if os.path.isfile(doc)]
folders = [folder for folder in path_dir_content if os.path.isdir(folder)]
# counter to keep track of amount of moved files
# and list of already created folders to avoid multiple creations
moved = 0
created_folders = []
print(f"Cleaning up {len(docs)} of {len(dir_content)} elements.")
与往常一样,让我们确保我们的用户得到反馈。因此,添加一条打印语句,以向用户指示要移动多少文件。
python directory_clean.py --path ./test
=> Cleaning up directory ./test
=> Cleaning up 60 of 60 elements.
重新执行python脚本后,我们现在可以看到/test我创建的文件夹包含60个将被移动的文件。
3.为每个文件扩展名创建一个文件夹
现在,下一步也是更重要的一步是为每个文件扩展名创建文件夹。为此,我们要浏览所有过滤的文件,如果它们的扩展名没有文件夹,请创建一个。
该os库可为我们提供更好的功能,例如拆分给定文档的文件类型和路径,提取路径本身和文档名称。
# go through all files and move them into according folders
for doc in docs:
# separte name from file extension
full_doc_path, filetype = os.path.splitext(doc)
doc_path = os.path.dirname(full_doc_path)
doc_name = os.path.basename(full_doc_path)
print(filetype)
print(full_doc_path)
print(doc_path)
print(doc_name)
break
上面代码末尾的break语句可确保如果目录中包含数十个文件,我们的终端也不会被发送垃圾邮件。
设置好之后,让我们执行脚本以查看类似于以下内容的输出:
python directory_clean.py --path ./test
=> ...
=> ./test/test17
=> ./test
=> test17
现在我们可以看到上面的实现分离了文件类型,然后从完整路径中提取了部分。
由于我们现在具有文件类型,因此我们可以检查是否存在具有该类型名称的文件夹。
在此之前,我们要确保跳过一些文件。如果我们使用当前目录"."作为路径,则需要避免移动python脚本本身。一个简单的if条件可以解决这个问题。
除此之外,我们不想移动“ 隐藏文件”,因此我们也包括所有以点开头的文件。.DS_StoremacOS上的文件是隐藏文件的示例。
# skip this file when it is in the directory
if doc_name == "directory_clean" or doc_name.startswith('.'):
continue
# get the subfolder name and create folder if not exist
subfolder_path = os.path.join(path, filetype[1:].lower())
if subfolder_path not in folders:
# create the folder
处理完python脚本和隐藏文件后,我们现在可以继续在系统上创建文件夹。
除了检查之外,如果在读取目录内容时文件夹已经存在,那么一开始,我们需要一种跟踪已创建文件夹的方法。这就是我们宣布该created_folders = []名单的原因。它将用作跟踪文件夹名称的存储器。
要创建一个新文件夹,该os库提供了一个名为的方法,该方法os.mkdir(folder_path)采用一个路径并在那里创建一个具有给定名称的文件夹。
此方法可能会引发异常,告诉我们该文件夹已存在。因此,我们还要确保捕获该错误。
if subfolder_path not in folders and subfolder_path not in created_folders:
try:
os.mkdir(subfolder_path)
created_folders.append(subfolder_path)
print(f"Folder {subfolder_path} created.")
except FileExistsError as err:
print(f"Folder already exists at {subfolder_path}... {err}")
设置文件夹创建后,让我们重新执行脚本。
python directory_clean.py --path ./test
=> ...
=> Folder ./test/pdf created.
在第一次执行时,我们可以看到一个日志列表,告诉我们已经创建了具有给定类型的文件扩展名的文件夹。
4.将每个文件移到右子文件夹中
现在的最后一步是将文件实际移到其新的父文件夹中。
使用os操作时要了解的重要一点是,有时无法撤消操作。例如,这就是删除的情况。因此,首先仅注销执行脚本将实现的行为是有意义的。
这就是为什么该os.rename(...)方法在这里被评论的原因。
# get the new folder path and move the file
new_doc_path = os.path.join(subfolder_path, doc_name) + filetype
# os.rename(doc, new_doc_path)
moved += 1
print(f"Moved file {doc} to {new_doc_path}")
执行完脚本并查看正确的日志记录之后,我们现在可以在os.rename()方法前删除注释哈希,并最终进行注释。
# get the new folder path and move the file
new_doc_path = os.path.join(subfolder_path, doc_name) + filetype
os.rename(doc, new_doc_path)
moved += 1
print(f"Moved file {doc} to {new_doc_path}")
print(f"Renamed {moved} of {len(docs)} files.")
python directory_clean.py --path ./test
=> ...
=> Moved file ./test/test17.pdf to ./test/pdf/test17.pdf
=> ...
=> Renamed 60 of 60 files.
现在,此最终执行会将所有文件移动到它们相应的文件夹中,并且无需手动操作即可很好地清理我们的目录。
在下一步中,我们现在可以使用上面创建的脚本,例如,安排它在每个星期一执行,以清理我们的Downloads文件夹以获得更多结构。
以上即是关于python如何实现日常工作自动化的全部内容,想了解更多关于python的信息,请继续关注中培教育吧。
相关阅读
- 大数据建模分析师课程培训05-11
- Python的就业前景07-05










预约领优惠
京ICP备13024721号-1
 京公网安备11010602007294号 增值电信业务经营许可证:京B2-20201348 全国统一报名专线:400-626-7377
京公网安备11010602007294号 增值电信业务经营许可证:京B2-20201348 全国统一报名专线:400-626-7377