
中培专家论-卷积神经网络(CNN)介绍与实践
1.1.大脑
作为人类,我们不断地通过眼睛来观察和分析周围的世界,我们不需要刻意的“努力”思考,就可以对所看到的一切做出预测,并对它们采取行动。当我们看到某些东西时,我们会根据我们过去学到的东西来标记每个对象。为了说明这些情况。
你可能会想到“这是一个快乐的小男孩站在椅子上”。或者也许你认为他看起来像是在尖叫,即将在他面前攻击这块蛋糕。
这就是我们整天下意识地做的事情。我们看到事物,然后标记,进行预测和识别行为。但是我们怎么做到这些的呢?我们怎么能解释我们看到的一切?
大自然花费了5亿多年的时间来创建一个系统来实现这一目标。眼睛和大脑之间的合作,称为主要视觉通路,是我们理解周围世界的原因。
虽然视力从眼睛开始,但我们所看到的实际解释发生在大脑的初级视觉皮层中。
当您看到一个物体时,您眼中的光感受器会通过视神经将信号发送到正在处理输入的主视觉皮层。在初级视觉皮层,使眼睛看到的东西的感觉。
所有这一切对我们来说都很自然。我们几乎没有想到我们能够识别我们生活中看到的所有物体和人物的特殊性。神经元和大脑连接的深层复杂层次结构在记忆和标记物体的过程中起着重要作用。
想想我们如何学习例如伞是什么。或鸭子,灯,蜡烛或书。一开始,我们的父母或家人告诉我们直接环境中物体的名称。我们通过给我们的例子了解到。慢慢地,但我们开始在我们的环境中越来越多地认识到某些事情。它们变得如此普遍,以至于下次我们看到它们时,我们会立即知道这个物体的名称是什么。他们成为我们世界的模型一部分。
1.2.卷积神经网络的历史
与孩子学会识别物体的方式类似,我们需要在能够概括输入并对之前从未见过的图像进行预测之前,展示数百万张图片的算法。
计算机以与我们不同的方式“看到”东西的。他们的世界只包括数字。每个图像都可以表示为二维数字数组,称为像素。
但是它们以不同的方式感知图像,这一事实并不意味着我们无法训练他们的识别模式,就像我们一样如何识别图像。我们只需要以不同的方式思考图像是什么。
为了“教会”一种算法如何识别图像中的对象,我们使用特定类型的人工神经网络:卷积神经网络(CNN)。他们的名字源于网络中最重要的一个操作:卷积。
卷积神经网络受到大脑的启发。DH Hubel和TN Wiesel在20世纪50年代和60年代对哺乳动物大脑的研究提出了哺乳动物如何在视觉上感知世界的新模型。他们表明猫和猴的视觉皮层包括在其直接环境中专门响应神经元的神经元。
在他们的论文中,他们描述了大脑中两种基本类型的视觉神经元细胞,每种细胞以不同的方式起作用:简单细胞(S细胞)和复合细胞(C细胞)。
例如,当简单单元格将基本形状识别为固定区域和特定角度的线条时,它们就会激活。复杂细胞具有较大的感受野,其输出对野外的特定位置不敏感。
复杂细胞继续对某种刺激做出反应,即使它在视网膜上的绝对位置发生变化。在这种情况下,复杂指的是更灵活。
在视觉中,单个感觉神经元的感受区域是视网膜的特定区域,其中某些东西将影响该神经元的发射(即,将激活神经元)。每个感觉神经元细胞都有相似的感受野,它们的田地覆盖着。
此外,层级【hierarchy 】的概念在大脑中起着重要作用。信息按顺序存储在模式序列中。的新皮层,它是大脑的最外层,以分层方式存储信息。它存储在皮质柱中,或者在新皮层中均匀组织的神经元分组。
1980年,一位名为Fukushima的研究员提出了一种分层神经网络模型。他称之为新认知。该模型的灵感来自简单和复杂细胞的概念。neocognitron能够通过了解物体的形状来识别模式。
后来,1998年,卷心神经网络被Bengio,Le Cun,Bottou和Haffner引入。他们的第一个卷积神经网络称为LeNet-5,能够对手写数字中的数字进行分类。
2、卷积神经网络
卷积神经网络(Convolutional Neural Network)简称CNN,CNN是所有深度学习课程、书籍必教的模型,CNN在影像识别方面的为例特别强大,许多影像识别的模型也都是以CNN的架构为基础去做延伸。另外值得一提的是CNN模型也是少数参考人的大脑视觉组织来建立的深度学习模型,学会CNN之后,对于学习其他深度学习的模型也很有帮助,本文主要讲述了CNN的原理以及使用CNN来达成99%正确度的手写字体识别。
CNN的概念图如下:
从上面三张图片我们可以看出,CNN架构简单来说就是:图片经过各两次的Convolution, Pooling, Fully Connected就是CNN的架构了,因此只要搞懂Convolution, Pooling, Fully Connected三个部分的内容就可以完全掌握了CNN!
2.1. convolution layer 卷积层
卷积运算就是将原始图片的与特定的Feature Detector(filter)做卷积运算(符号?),卷积运算就是将下图两个3x3的矩阵作相乘后再相加,以下图为例0 *0 + 0*0 + 0*1+ 0*1 + 1 *0 + 0*0 + 0*0 + 0*1 + 0*1 =0
每次移动一步,我们可以一次做完整张表的计算,如下:
下面的动图更好地解释了计算过程:
左:过滤器在输入上滑动。右:结果汇总并添加到要素图中。
中间的Feature Detector(Filter)会随机产生好几种(ex:16种),Feature Detector的目的就是帮助我们萃取出图片当中的一些特征(ex:形状),就像人的大脑在判断这个图片是什么东西也是根据形状来推测
利用Feature Detector萃取出物体的边界
利用Feature Detector萃取出物体的边界
使用Relu函数去掉负值,更能淬炼出物体的形状
我们在输入上进行了多次卷积,其中每个操作使用不同的过滤器。这导致不同的特征映射。最后,我们将所有这些特征图放在一起,作为卷积层的最终输出。
就像任何其他神经网络一样,我们使用激活函数使输出非线性。在卷积神经网络的情况下,卷积的输出将通过激活函数。这可能是ReLU激活功能
这里还有一个概念就是步长,Stride是每次卷积滤波器移动的步长。步幅大小通常为1,意味着滤镜逐个像素地滑动。通过增加步幅大小,您的滤波器在输入上滑动的间隔更大,因此单元之间的重叠更少。
下面的动画显示步幅大小为1。
由于feature map的大小始终小于输入,我们必须做一些事情来防止我们的要素图缩小。这是我们使用填充的地方。
添加一层零值像素以使用零环绕输入,这样我们的要素图就不会缩小。除了在执行卷积后保持空间大小不变,填充还可以提高性能并确保内核和步幅大小适合输入。
可视化卷积层的一种好方法如下所示,最后我们以一张动图解释下卷积层到底做了什么
卷积如何与K = 2滤波器一起工作,每个滤波器具有空间范围F = 3,步幅S = 2和输入填充P = 1.
2.2.pooling layer 池化层
在卷积层之后,通常在CNN层之间添加池化层。池化的功能是不断降低维数,以减少网络中的参数和计算次数。这缩短了训练时间并控制过度拟合。
最常见的池类型是max pooling,它在每个窗口中占用最大值。需要事先指定这些窗口大小。这会降低特征图的大小,同时保留重要信息。
Max Pooling主要的好处是当图片整个平移几个Pixel的话对判断上完全不会造成影响,以及有很好的抗杂讯功能。
2.3.Fully Connected Layer 全连接层
基本上全连接层的部分就是将之前的结果平坦化之后接到最基本的神经网络了
3、利用CNN识别MNIST手写字体
下面这部分主要是关于如何使用tensorflow实现CNN以及手写字体识别的应用:
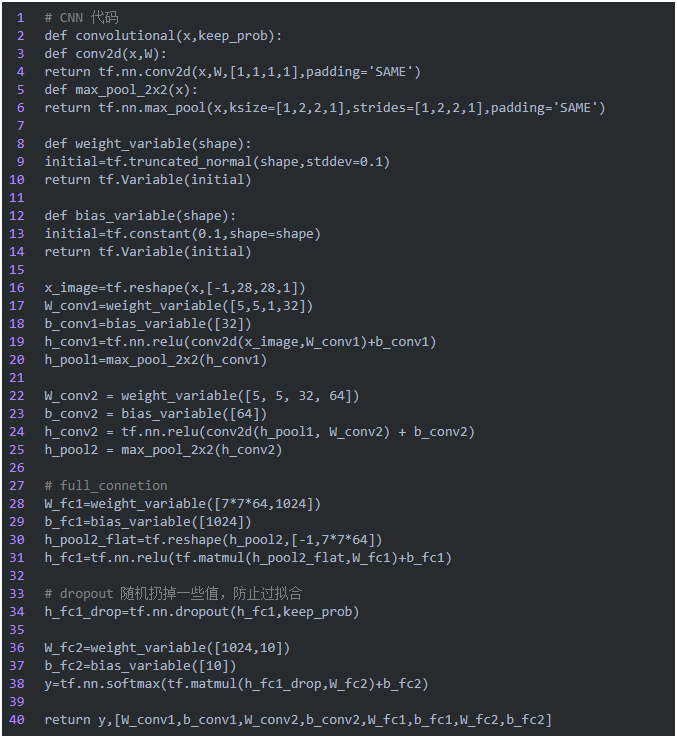
大家稍微对tensorflow的代码有些基础,理解上面这部分基本上没有难度,并且基本也是按照我们前面概念图中的逻辑顺序实现的。
最终按照慕课网上的学习资料TensorFlow与Flask结合打造手写体数字识别,实现了一遍CNN,比较曲折的地方是前端,以 及如何将训练的模型与flask整合,最后项目效果如下:
4、总结
最后说自己的两点感触吧:
1、CNN在各种场景已经应用很成熟,网上资料特别多,原先自己也是略知一二,但是从来没有总结整理过,还是整理完之后心里比较踏实一些。
2、切记理论加实践,实现一遍更踏实。
想了解更多IT资讯,请访问中培教育官网:中培教育
相关阅读










预约领优惠
京ICP备13024721号-1
 京公网安备11010602007294号 增值电信业务经营许可证:京B2-20201348 全国统一报名专线:400-626-7377
京公网安备11010602007294号 增值电信业务经营许可证:京B2-20201348 全国统一报名专线:400-626-7377